每日經(jīng)濟(jì)新聞
2025-04-07 17:02


開源大模型元老,,發(fā)布重磅更新。
北京時間4月6日凌晨,,美國科技巨頭Meta推出了開源人工智能模型Llama 4,。據(jù)介紹,該模型目前目前有Scout和Maverick兩個版本,,是Meta迄今為止最先進(jìn)的模型,,也是同類產(chǎn)品中多模態(tài)性最強(qiáng)的模型。
在DeepSeek引發(fā)模型開源浪潮以前,,Meta一直是開源模型的領(lǐng)先玩家及重要的行業(yè)奠基者。在ChatGPT橫空出世7個多月后,,Meta就率先宣布開源Llama 2,,并且可免費商用,。這也成為大模型發(fā)展的分水嶺,是開源模型社區(qū)的歷史性時刻,。Llama第四代模型的發(fā)布,,不僅是Meta應(yīng)對DeepSeek等新興開源勢力的一次“回?fù)簟保瑫r也推動了開源模型技術(shù)的進(jìn)一步發(fā)展和生態(tài)的進(jìn)一步完善,。

大規(guī)模,、多模態(tài)、長文本的Llama 4發(fā)布
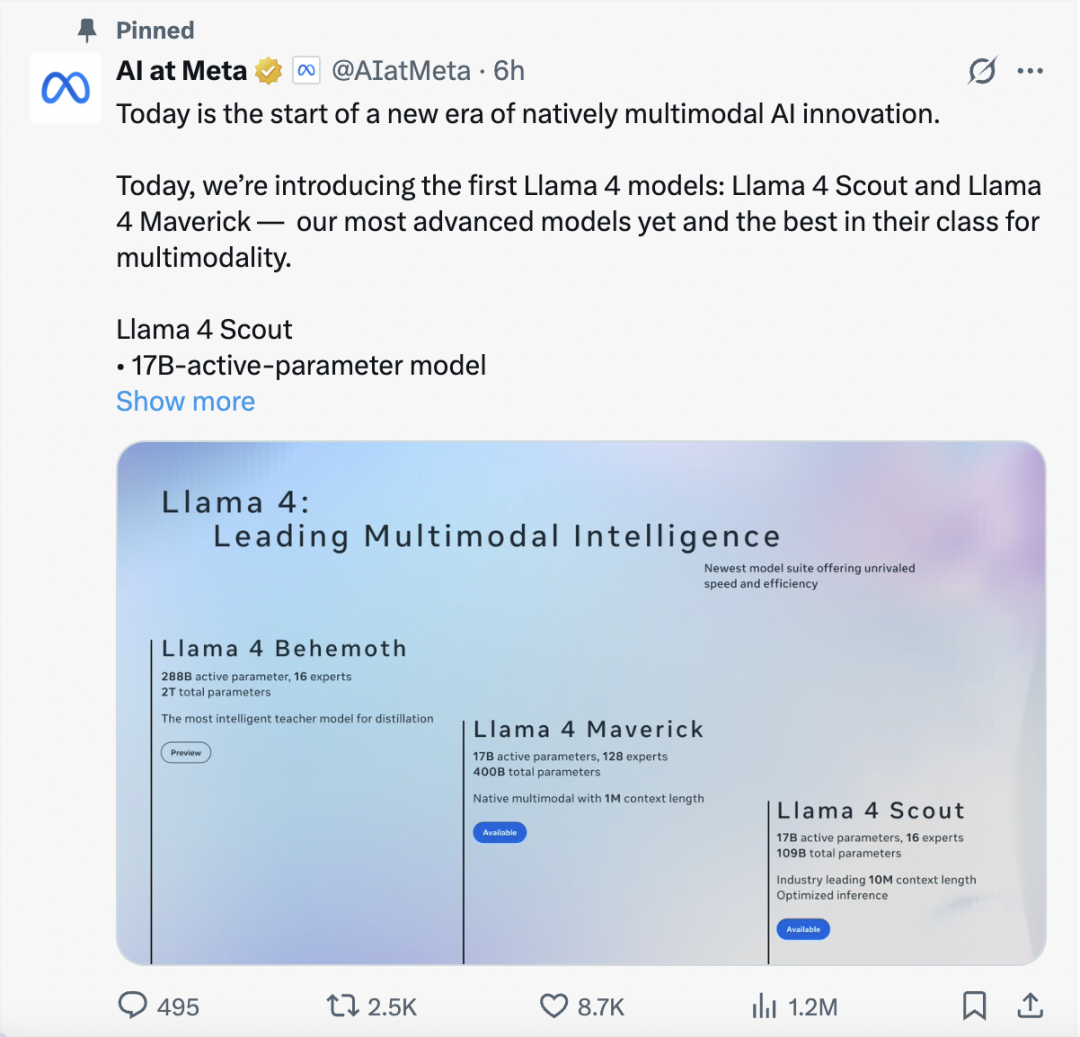
北京時間4月6日凌晨,,Meta發(fā)布Llama 4系列首批模型,,包括兩款高效模型Llama 4 Scout、Llama 4 Maverick,。此外,,Meta還預(yù)覽了其迄今最強(qiáng)大最智能的模型——Llama 4 Behemoth,是“新模型中的教師”,。
Llama 4模型是Llama系列模型中首批采用混合專家(MoE)架構(gòu)的模型,。這一模型也是DeepSeek系列模型采用的架構(gòu),與傳統(tǒng)的稠密模型相比,,在MoE架構(gòu)中,,單獨的token只會激活全部參數(shù)中的一小部分,訓(xùn)練和推理的計算效率更高,。
首先,,Llama 4的第一大特點是參數(shù)規(guī)模大,最先進(jìn)的Llama 4 Behemoth總參數(shù)高達(dá)2萬億(作為對照,,DeepSeek-R1總參數(shù)規(guī)模為6710億),。
其中,Llama 4 Scout面向文檔摘要與大型代碼庫推理任務(wù),,專為高效信息提取與復(fù)雜邏輯推理打造,,共有16位“專家”、1090億參數(shù),、170億激活參數(shù)量,;Llama 4 Maverick則專注于多模態(tài)能力,支持視覺和語音輸入,,具備頂級的多語言支持與編程能力,,共有128位“專家”、4000億參數(shù),、170億激活參數(shù)量,;Llama 4 Behemoth(預(yù)覽版)則是Meta未來最強(qiáng)大的AI模型之一,具備令人矚目的超大規(guī)模參數(shù)架構(gòu),,具有2880億激活參數(shù)量,,總參數(shù)高達(dá)2萬億,。
其次,Llama 4的另外一大特點是多模態(tài)能力突出,。作為原生多模態(tài)模型,,Llama 4采用了早期融合(Early Fusion)技術(shù),可以用海量的無標(biāo)簽文本,、圖片和視頻數(shù)據(jù)一起來預(yù)訓(xùn)練模型,,實現(xiàn)文本和視覺token無縫整合到統(tǒng)一的模型框架里。
據(jù)Meta介紹,,Llama用各種圖像和視頻幀靜止圖像訓(xùn)練兩個模型,,以賦予它們廣泛的視覺理解能力,包括時間活動和相關(guān)圖像,。這支持多圖像輸入與文本提示的無縫交互,,用于視覺推理和理解任務(wù)。模型在預(yù)訓(xùn)練中最多使用48張圖像,,后訓(xùn)練中測試了最多8張圖像,,結(jié)果良好。
最后,,Llama在長文本能力上也取得了突破,,具有超大的上下文窗口長度。Llama 4 Scout 模型支持高達(dá)1000萬token的上下文窗口,,刷新了開源模型的紀(jì)錄,,而市場上其他領(lǐng)先模型如GPT-4o也未能達(dá)到此規(guī)模。超大上下文窗口使Llama 4在處理長文檔,、復(fù)雜對話和多輪推理任務(wù)時表現(xiàn)出色,。
大模型競爭趨于白熱化
作為開源模型社區(qū)的“領(lǐng)頭羊”和佼佼者,Llama(Large Language Model Meta AI)系列模型由Meta在2022年推出,。2023年,,為應(yīng)對ChatGPT等領(lǐng)先閉源模型的挑戰(zhàn),Meta率先宣布開源Llama 2,,并且可免費商用,。這一開源之舉激活了開發(fā)者社區(qū)的創(chuàng)新潛力,此后基于Llama 2構(gòu)建的應(yīng)用項目數(shù)量大大增加,,覆蓋各種領(lǐng)域,,形成了一個充滿活力的生態(tài)系統(tǒng)。
2024年4月,,Llama 3正式發(fā)布,,在技術(shù)層面實現(xiàn)了諸多突破,最重要的是不僅在單語言任務(wù)上表現(xiàn)卓越,還實現(xiàn)了多模態(tài)處理能力,,能夠同時理解并生成文本,、圖像、音頻等多種類型的數(shù)據(jù),,從而開啟了多模態(tài)的新紀(jì)元。
雖然Meta是開源模型的重要奠基者,,但是開源領(lǐng)域的競爭正變得日益激烈和焦灼,,尤其是DeepSeek的崛起,對Meta在開源模型社區(qū)的領(lǐng)先地位構(gòu)成了巨大的沖擊,。
今年1月末,,在DeepSeek剛剛在海外火爆出圈時,就有Meta員工在匿名社區(qū)TeamBlind上爆料稱,,僅用550萬美元訓(xùn)練的DeepSeek-V3在基準(zhǔn)測試中已經(jīng)讓Llama模型相形見絀,,Meta的工程師們正在爭分奪秒地分析DeepSeek,試圖復(fù)制其中的一切可能技術(shù),。該爆料帖還說,,Meta管理層正面臨嚴(yán)峻的財務(wù)壓力,其生成式AI部門數(shù)十位高管,,“每個人的年薪都超過了DeepSeek-V3的全部訓(xùn)練費用,。如何向公司高層解釋這種投入產(chǎn)出比,已成為他們的噩夢”,。
除了DeepSeek以外,,阿里巴巴通義千問系列開源大模型也屢屢斬獲佳績。4月2日,,全球最大的AI開源社區(qū)Hugging Face更新了大模型榜單,,阿里通義千問近期開源的端到端全模態(tài)大模型Qwen2.5-Omni登上總榜榜首。據(jù)了解,,阿里至今已向全球開源200多款模型,,千問衍生模型數(shù)量已突破10萬,超越美國Llama系列,,成為全球最大的開源模型族群,。
在Llama 4發(fā)布之際,OpenAI首席執(zhí)行官山姆·奧特曼也對外透露了公司的模型發(fā)布計劃,。他表示,,OpenAI可能在幾周后發(fā)布最新的推理模型o3和最新的基座模型o4-mini,然后在幾個月后推出GPT-5,。
DeepSeek-R2模型何時發(fā)布也備受市場關(guān)注,。4月4日,DeepSeek與清華大學(xué)研究團(tuán)隊聯(lián)合發(fā)布題為《獎勵模型的推理時Scaling方法及其在大規(guī)模語言模型中的應(yīng)用》的重磅論文,,提出自我原則點評調(diào)優(yōu)(SPCT)與元獎勵模型(Meta Reward Model)兩項核心技術(shù),,為提升大語言模型的推理能力提供了全新方法論,。雖然官方并未明確R2的發(fā)布時間,但這一成果被視為DeepSeek下一代推理模型R2的重要技術(shù)鋪墊,。
技術(shù)的不斷突破及各家大模型的密集推出,,表明大模型競爭趨于白熱化,彼此間你追我趕將是未來一段時間的常態(tài),。業(yè)內(nèi)人士分析稱,,模型能力的持續(xù)提升,推動大模型競爭進(jìn)入推理強(qiáng)化和應(yīng)用拓展的下半場賽程,。個人智能體潛力初步顯現(xiàn),,行業(yè)應(yīng)用漸次走深,開源開放日益成為大模型的核心競爭力組成,。大算力,、多模態(tài)、強(qiáng)推理,、廣開源,、準(zhǔn)數(shù)據(jù)、智能體,、深應(yīng)用等,,成為大模型發(fā)展的重要趨勢。
責(zé)編:李丹
校對:劉榕枝