證券時報網(wǎng)
2025-01-31 13:29


英偉達也認可了!
據(jù)英偉達官網(wǎng)最新消息,,為了幫助開發(fā)人員安全地試驗這些功能并構(gòu)建自己的專用代理,,6710億參數(shù)的DeepSeek-R1模型現(xiàn)已作為NVIDIA NIM微服務(wù)預(yù)覽版在Build.nvidia.com上提供。DeepSeek-R1 NIM微服務(wù)可以在單個NVIDIA HGX H200系統(tǒng)上每秒提供多達3872個令牌,。開發(fā)人員可以使用應(yīng)用程序編程接口(API)進行測試和試驗,,該接口預(yù)計很快將作為可下載的NIM微服務(wù)提供,是NVIDIA AI Enterprise軟件平臺的一部分,。
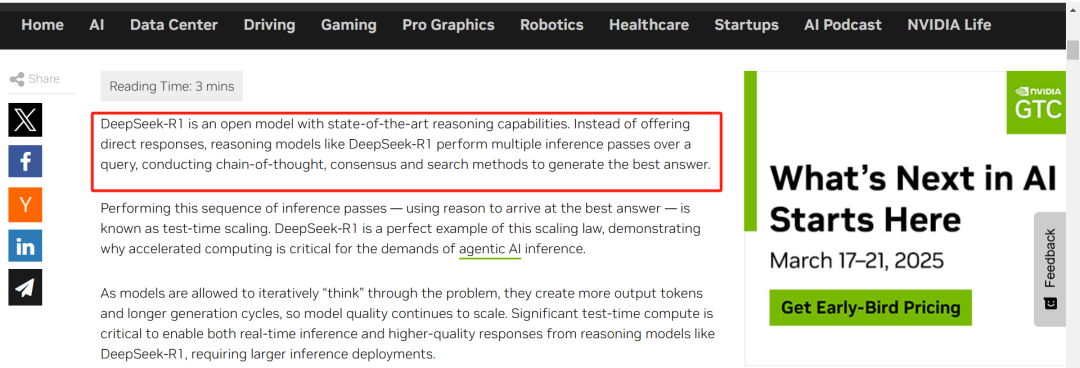
此外,,英偉達還在官網(wǎng)中表示,DeepSeek-R1是一個具有最先進推理能力的開放模型,。DeepSeek-R1等推理模型不會提供直接響應(yīng),,而是對查詢進行多次推理,采用思路鏈,、共識和搜索方法來生成最佳答案,。

來自英偉達的認可
英偉達稱,DeepSeek-R1等推理模型不會提供直接響應(yīng),,而是對查詢進行多次推理,,采用思路鏈、共識和搜索方法來生成最佳答案,。執(zhí)行這一系列推理過程(使用推理得出最佳答案)稱為測試時間擴展。DeepSeek-R1是此擴展定律的完美示例,,證明了加速計算對于代理AI推理的需求至關(guān)重要,。
由于模型可以反復(fù)“思考”問題,因此它們會創(chuàng)建更多輸出標(biāo)記和更長的生成周期,,因此模型質(zhì)量會不斷提高,。大量的測試時計算對于實現(xiàn)實時推理和來自DeepSeek-R1等推理模型的更高質(zhì)量響應(yīng)至關(guān)重要,這需要更大規(guī)模的推理部署,。R1在需要邏輯推理,、推理、數(shù)學(xué),、編碼和語言理解的任務(wù)中提供了領(lǐng)先的準(zhǔn)確性,,同時還提供了高推理效率。
為了幫助開發(fā)人員安全地試驗這些功能并構(gòu)建自己的專用代理,,6710億參數(shù)的DeepSeek-R1模型現(xiàn)已作為NVIDIA NIM微服務(wù)預(yù)覽版在Build.nvidia.com上提供,。DeepSeek-R1 NIM微服務(wù)可以在單個NVIDIA HGX H200系統(tǒng)上每秒提供多達3872個令牌。開發(fā)人員可以使用應(yīng)用程序編程接口(API)進行測試和試驗,,該接口預(yù)計很快將作為可下載的NIM微服務(wù)提供,,是NVIDIA AI Enterprise軟件平臺的一部分。
DeepSeek-R1 NIM微服務(wù)通過支持行業(yè)標(biāo)準(zhǔn)API簡化了部署,。企業(yè)可以通過在其首選的加速計算基礎(chǔ)設(shè)施上運行NIM微服務(wù)來最大限度地提高安全性和數(shù)據(jù)隱私,。通過使用NVIDIA AI Foundry和NVIDIA NeMo軟件,,企業(yè)還可以為專門的AI代理創(chuàng)建定制的DeepSeek-R1 NIM微服務(wù)。
DeepSeek-R1是一個大型混合專家(MoE)模型,。它包含了令人印象深刻的6710億個參數(shù)——比許多其他流行的開源LLM多10倍——支持128000個Token的大輸入上下文長度,。該模型還在每個層中使用了極多的專家。R1的每一層都有256位專家,,每個Token并行路由到八個不同的專家進行評估,。
為R1提供實時答案需要許多具有高計算性能的GPU,并通過高帶寬和低延遲通信進行連接,,以將提示令牌路由到所有專家進行推理,。結(jié)合NVIDIA NIM微服務(wù)中提供的軟件優(yōu)化,一臺使用NVLink和NVLink Switch連接的帶有八個H200 GPU的服務(wù)器可以以每秒高達3872個令牌的速度運行完整的6710億參數(shù)DeepSeek-R1模型,。這種吞吐量是通過在每一層使用 NVIDIA Hopper 架構(gòu)的FP8 Transformer Engine實現(xiàn)的,,并且使用900GB/s的NVLink帶寬進行MoE專家通信。
充分利用GPU的每秒浮點運算(FLOPS)性能對于實時推理至關(guān)重要,。下一代NVIDIA Blackwell架構(gòu)將通過第五代Tensor Core大幅提升 DeepSeek-R1等推理模型的測試時間擴展,,第五代Tensor Core可提供高達20 petaflops的峰值FP4計算性能,以及專門針對推理優(yōu)化的72-GPU NVLink域,。
從開源到復(fù)現(xiàn)
近日,,加州大學(xué)伯克利分校的研究人員開發(fā)出了中國開發(fā)的 AI 語言模型DeepSeek R1-Zero的小規(guī)模語言模型復(fù)制品,成本約為30美元,。語言模型TinyZero是由校園研究生Jiayi Pan和其他三名研究人員領(lǐng)導(dǎo)的項目,,由校園教授Alane Suhr教授和伊利諾伊大學(xué)厄巴納-香檳分校助理教授Hao Peng指導(dǎo)。
DeepSeek的R1模型權(quán)重和代碼庫采用公共MIT許可證,,因此Pan和他的團隊能夠訪問基礎(chǔ)代碼來訓(xùn)練一個明顯小得多的模型,。潘表示,TinyZero同樣是開源的,,這意味著代碼可供公眾使用,。他說,TinyZero 的開源性質(zhì)允許人們下載代碼并嘗試訓(xùn)練和修改模型,?!靶∫?guī)模復(fù)制非常容易實現(xiàn),而且成本非常低,,即使人們將其作為實驗的副項目,,”潘說?!皬捻椖恳婚_始,,我們的目標(biāo)基本上就是揭開如何訓(xùn)練這些模型的神秘面紗,更好地理解它們背后的科學(xué)和設(shè)計決策?!?/p>
昨天,,微軟官網(wǎng)顯示,DeepSeek R1現(xiàn)已在Azure AI Foundry和 GitHub上的模型目錄中提供,,加入了1800多個模型的多樣化產(chǎn)品組合,,包括前沿、開源,、行業(yè)特定和基于任務(wù)的AI模型,。作為Azure AI Foundry的一部分,DeepSeek R1可在值得信賴,、可擴展且企業(yè)級就緒的平臺上訪問,,使企業(yè)能夠無縫集成高級AI,同時滿足SLA,、安全性和負責(zé)任的AI承諾——所有這些都由Microsoft的可靠性和創(chuàng)新支持,。
黑石最新態(tài)度
本周,硅谷,、華盛頓,、華爾街等地的領(lǐng)導(dǎo)人因中國人工智能公司DeepSeek的意外崛起而陷入混亂。許多分析師認為DeepSeek的成功動搖了推動美國人工智能行業(yè)發(fā)展的核心信念,。
但人工智能科學(xué)家反駁說,,許多擔(dān)憂都是夸大其詞。他們表示,,盡管DeepSeek確實代表了人工智能效率的真正進步,,但美國人工智能行業(yè)仍然具有關(guān)鍵優(yōu)勢。蘭德公司人工智能研究員倫納特·海姆表示:“這并不是人工智能前沿能力的飛躍,。我認為市場只是搞錯了?!?/p>
另外,,截至目前,私募股權(quán)巨頭,、全球主要人工智能系統(tǒng)數(shù)據(jù)中心投資者黑石集團仍持樂觀態(tài)度,。“我們?nèi)匀徽J為,,實體基礎(chǔ)設(shè)施,、數(shù)據(jù)中心和電力的需求十分迫切,”黑石總裁喬納森·格雷(Jonathan Gray)周四在與投資者舉行的第四季度財報電話會議上表示,?!斑@些需求的使用方式可能會發(fā)生變化。”
格雷表示,,與投資界和企業(yè)界的大多數(shù)人一樣,,黑石集團的高管在過去一周花了大量時間來權(quán)衡DeepSeek的影響。近年來,,黑石集團積極購買和建設(shè)數(shù)據(jù)中心,,這是科技公司運行人工智能系統(tǒng)所使用的物理基礎(chǔ)設(shè)施。2021年,,黑石集團以100億美元收購了美國數(shù)據(jù)中心公司QTS,,去年,黑石集團牽頭以約160億美元收購了在亞洲運營數(shù)據(jù)中心的AirTrunk,。
格雷同時預(yù)計,,隨著人工智能計算能力成本的大幅下降,人工智能將得到更廣泛的應(yīng)用,。換句話說,,雖然人工智能模型回答特定問題所需的能力可能會減少,但人們會提出更多問題,。格雷表示,,黑石集團只為簽訂長期租約的科技公司建造數(shù)據(jù)中心?!拔覀儾粫稒C性地建造它們,。”他指出,,客戶使用這些數(shù)據(jù)中心的方式很可能會改變,。
責(zé)編:羅曉霞
校對:楊立林