
證券時報網(wǎng)
司維
2025-02-24 22:10


萬眾矚目的DeepSeek“開源周”,第一彈來了。
2月24日,,DeepSeek開源了首個代碼庫FlashMLA,。據(jù)了解,這是DeepSeek針對Hopper GPU優(yōu)化的高效MLA(Multi-Head Latent Attention,,多頭潛在注意力)解碼內核,,專為處理可變長度序列而設計,現(xiàn)在已經投入生產使用,。

上周四,,DeepSeek宣布將在本周舉辦“開源周”活動,連續(xù)開源五個代碼庫,,由此引燃了大家的期待,。作為“開源周”的第一彈,F(xiàn)lashMLA給業(yè)界帶來頗多驚喜,。本周的剩下四個工作日,,DeepSeek還將繼續(xù)開源四個代碼庫。業(yè)內人士分析,,其余四個代碼庫可能會與AI算法優(yōu)化,、模型輕量化、應用場景拓展等相關,,涵蓋多個關鍵領域,。
進一步突破GPU算力瓶頸
根據(jù)DeepSeek的介紹,F(xiàn)lashMLA主要實現(xiàn)了以下的突破:
一是BF16支持,,提供更高效的數(shù)值計算能力,,減少計算精度損失,同時優(yōu)化存儲帶寬使用率,。
二是分頁KV(Key-Value,,一種緩存機制)緩存,采用高效的分塊存儲策略,,減少長序列推理時的顯存占用,,提高緩存命中率,從而提升計算效率,。
三是極致性能優(yōu)化,,在H800GPU上,F(xiàn)lashMLA通過優(yōu)化訪存和計算路徑,,達到了3000GB/s內存帶寬和580TFLOPS的計算能力,,最大化利用GPU資源,減少推理延遲,。
據(jù)了解,,傳統(tǒng)解碼方法在處理不同長度的序列時,,GPU的并行計算能力會被浪費,就像用卡車運小包裹,,大部分空間閑置,。而FlashMLA通過動態(tài)調度和內存優(yōu)化,將HopperGPU的算力“榨干”,,提升相同硬件下的吞吐量,。
簡單理解,F(xiàn)lashMLA能夠讓大語言模型在H800這樣的GPU上跑得更快,、更高效,,尤其適用于高性能AI任務,進一步突破GPU算力瓶頸,,降低成本,。
值得注意的是,DeepSeek之所以能夠實現(xiàn)大模型訓練與成本的大幅降低,,與其提出的創(chuàng)新注意力架構MLA密不可分,。MLA(多頭潛在注意力機制)又被稱為低秩注意力機制,是與傳統(tǒng)的多頭注意力機制(Multi-head Attention)不同的一種創(chuàng)新性注意力機制,。自從V2模型開始,,MLA就幫助DeepSeek在一系列模型中實現(xiàn)成本大幅降低,但是計算,、推理性能仍能與頂尖模型持平,。
浙江大學計算機科學與技術學院和軟件學院黨委書記、人工智能研究所所長吳飛表示,,我們理解一篇文章,更關切單詞所刻畫的主題概念,,而非單詞從頭到尾的羅列等,。傳統(tǒng)大模型中的注意力機制由于需要記錄每個單詞在不同上下文中的左鄰右舍,因此其變得龐大無比,。DeepSeek引入低秩這一概念,,對巨大的注意力機制矩陣進行了壓縮,減少參與運算的參數(shù)數(shù)量,,從而在保持模型性能的同時顯著降低了計算和存儲成本,,把顯存占用降到了其他大模型的5%-13%,極大提升了模型運行效率,。
由于Flash MLA進一步突破了GPU算力瓶頸,,記者注意到,有英偉達股民跑到DeepSeek的評論區(qū)祈禱,,希望DeepSeek在讓GPU更為高效的同時,,能夠不影響英偉達的股價,。

以持續(xù)開源加速行業(yè)發(fā)展進程
作為開源社區(qū)的“頂流”,DeepSeek以完全透明的方式與全球開發(fā)者社區(qū)分享最新的研究進展,,加速行業(yè)發(fā)展進程,。
在開源公告中,DeepSeek還表示,,自己只是探索通用人工智能的小公司,,作為開源社區(qū)的一部分,每分享一行代碼,,都會成為加速AI行業(yè)發(fā)展的集體動力,。同時,DeepSeek稱,,沒有高不可攀的象牙塔,,只有純粹的車庫文化和社區(qū)驅動的創(chuàng)新。
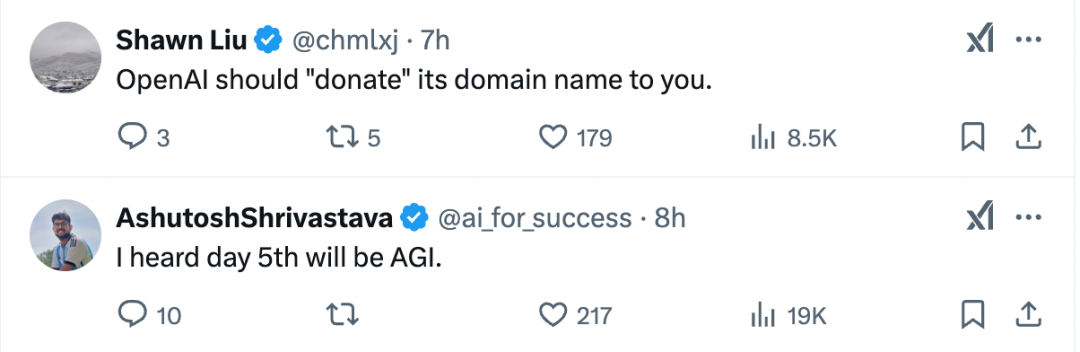
記者注意到,,在DeepSeek開源FlashMLA的帖子下,,有不少網(wǎng)友點贊其公開透明的開源精神。有網(wǎng)友表示,,“OpenAI應該將它的域名捐給你”,,還有網(wǎng)友說,“(開源周)第五天,,我猜會是通用人工智能”,。
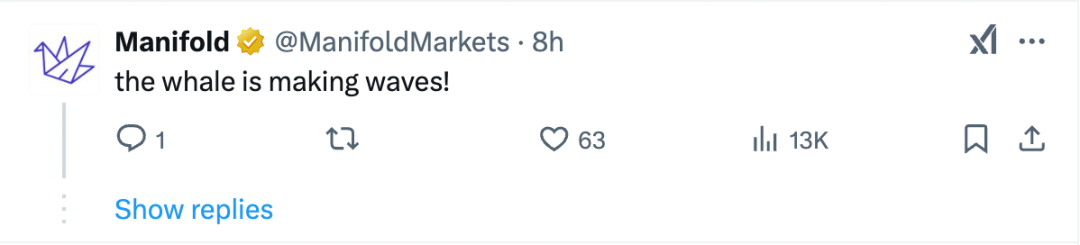
由于DeepSeek的圖標是一只在大海里探索的鯨魚,還有網(wǎng)友形象生動地描述稱,,“這條鯨魚正在掀起波浪”(The whale is making waves),。
據(jù)證券時報記者了解,(Open Source Initiative,,開源代碼促進會)專門針對AI提出了三種開源概念,,分別是:
開源AI系統(tǒng):包括訓練數(shù)據(jù)、訓練代碼和模型權重,。代碼和權重需要按照開源協(xié)議提供,,而訓練數(shù)據(jù)只需要公開出處(因為一些數(shù)據(jù)集確實無法公開提供)。
開源AI模型:只需要提供模型權重和推理代碼,,并按照開源協(xié)議提供,。(所謂推理代碼,就是讓大模型跑起來的代碼,。這是一個相當復雜的系統(tǒng)性工程,,涉及到了GPU調用和模型架構)。
開源AI權重:只需要提供模型權重,,并按照開源協(xié)議提供,。
業(yè)內普遍認為,,DeepSeek的勝利是開源的勝利,開源大模型的創(chuàng)新模式為人工智能的發(fā)展開辟了新的路徑,。DeepSeek此前開源的是模型權重,,并沒有開放訓練代碼、推理代碼,、評估代碼,、數(shù)據(jù)集等更為重要的組件,因此屬于第三種類型的開源,。
一名資深的業(yè)內人士告訴記者,,在DeepSeek推出R1并發(fā)布技術報告后,許多團隊都在試圖復現(xiàn)R1模型,,但由于背后還涉及許多重要和關鍵的技術細節(jié),,因此要實現(xiàn)真正的復現(xiàn)其實比較困難,而且也需要較長的時間,。不過,,業(yè)內的開源基本上也都是開源模型權重,而DeepSeek的開源與其他開源模型相比已經是最頂級,、最徹底的一種,。
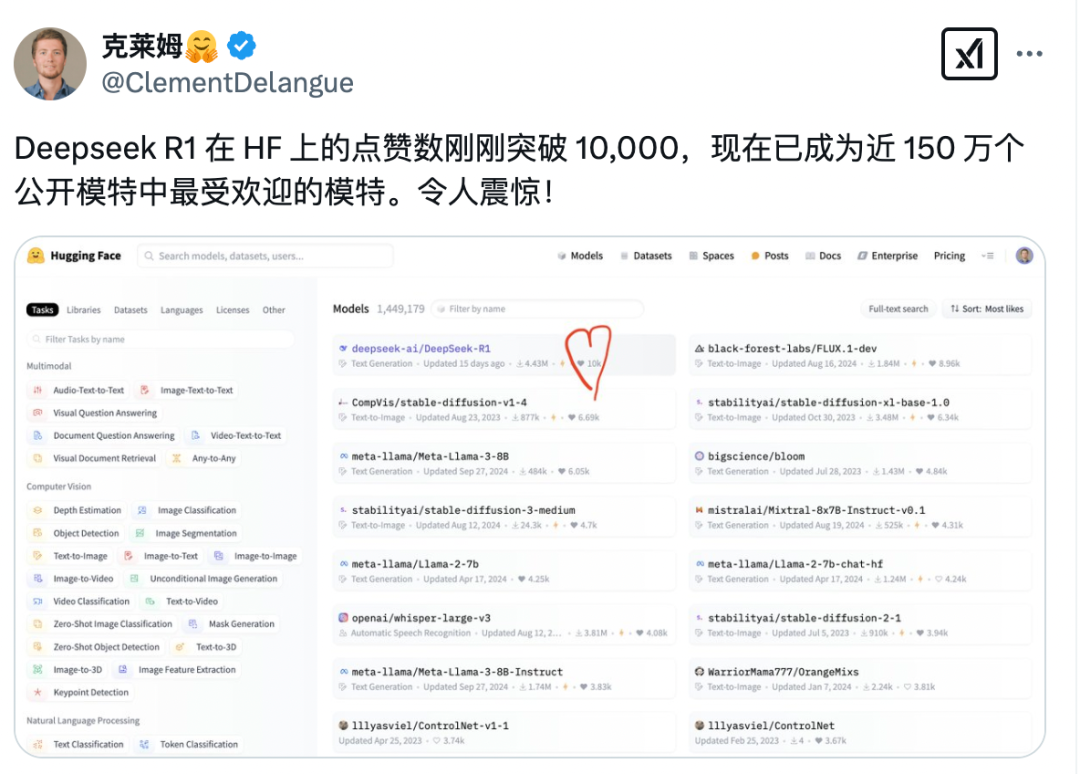
正因如此,DeepSeek也被業(yè)界稱為“源神”,。同樣在今天,,DeepSeek-R1在知名的國際開源社區(qū)Hugging Face上獲得了超過一萬個贊,成為該平臺近150萬個模型之中最受歡迎的大模型,。Hugging Face的首席執(zhí)行官Clement Delangue也在社交平臺上第一時間分享了這一喜訊,。
民生證券研報認為,DeepSeek所有模型均為開源模型,,即所有應用廠商都擁有了可以比肩頂級AI的大模型,,而且還可自行二次開發(fā)、靈活部署,,這將加速AI應用的發(fā)展進程。當模型的成本越低,,開源模型發(fā)展越好,,模型的部署、使用的頻率就會越高,,使用量就會越大,。
研報進一步指出,經濟學上著名的“杰文斯悖論”提出,,當技術進步提高了資源使用的效率,,不僅沒有減少這種資源的消耗,,反而因為使用成本降低,刺激了更大的需求,,最終導致資源使用總量上升,。因此從更長的周期來看,DeepSeek的發(fā)展恰恰會加速AI的普及和創(chuàng)新,,帶來算力需求,、特別是推理算力需求更大量級提升。
校對:蘇煥文







